

캐시가 무엇?
system 설계를 하다가 'Cache'라는 용어를 잘못 사용하다가 멘토에게 지적을 받은 적이 있다. 상황을 대략 설명하자면, system에 Spring으로 구현한 WAS가 여럿 있었고, 거기에 세션을 관리할 Redis가 붙어있었는데, 그 Redis를 '웹캐시'라고 칭하다가 지적을 받은 것이다.
구글에 '캐시 DB'라고 검색하면 Redis에 대한 블로그 글이 많이 나온다. 그러다보니 'Redis = 캐시 DB'라고 잘못 인식한 것 같다. 하지만 엄연히 따져보니, Redis는 캐시 DB가 아니다. Redis는 캐시의 역할을 할 수 있는 in-memory DB인 것이다. 즉, Redis를 캐시로 사용할 순 있어도 Redis 그 자체를 캐시라고 칭하는 건 잘못된 것이다.
또한, 설령 잘못 칭한다 하더라도 Redis를 그냥 '캐시'라고 칭했으면 됐을 텐데, 하필 이것을 '웹 캐시'라고 말했기 때문에 더욱 잘못된 용어를 사용하여 혼돈을 가중시켰다. '웹 캐시'는 후술하겠지만, 주로 프록시 서버(혹은 CDN)를 칭하는 용어이기 때문이다. 즉, Redis를 웹 캐시라고 칭한 것은 용어를 잘못 사용한 것이다.
이쯤 되니 CPU에 달려있는 '캐시'도 생각날 법하다. '그 캐시랑 이 캐시는 무슨 차이가 있는거지? 둘이 동일한건가?' 아니 그럴리가 없다. 하나는 그냥 컴퓨터 안에 있는 캐시를 말하는 것이고, 하나는 네트워크가 있어야 성립이 되는 캐시다. 같을 리가 없다. 이처럼 캐시로 칭하는 대상이 워낙 다양하다 보니 혼란이 올 법 하다. 이번 글에선 이러한 혼란을 피하기 위해 "캐시"에 대해 제대로 정리해본다.
Cache의 사전적 정의
Cambridge dictionary에 "cache"를 검색하면 아래와 같이 나온다.
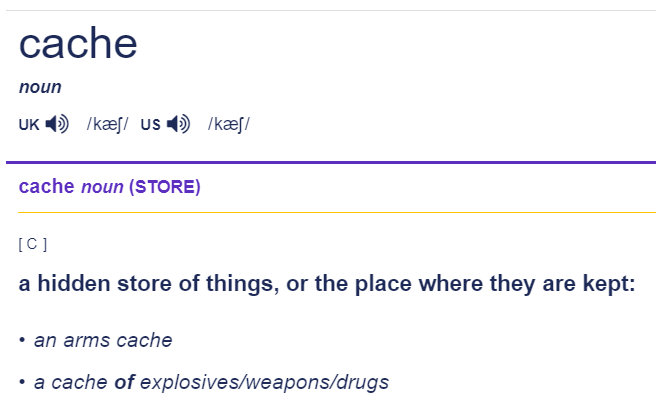
우리말로 하면 '은닉처' 정도 되겠다.
이렇게 "캐시"는 일반 명사로 사용되고 있던 단어였고, CS에서는 '저장소'라는 개념을 빌려왔던 것이다.

이렇게 "저장소"라는 개념을 빌려와 여러 대상에 대해 "캐시"라는 용어를 사용하고 있었던 것이다.
Computer 용어로 "캐시"라고 하면 일반적으로 "임시 저장소"라고 생각하면 될 것 같다.
Computer Science에서 캐시의 종류
흔히 캐시를 말할 때 혼란이 오기 쉬운 이유가 캐시가 칭하는 대상이 워낙 다양하기 때문이다. CS에서 캐시는 다음과 같이 다양한 캐시가 존재한다.
1. CPU Cache
2. Disk Cache
3. Proxy Server(Web Cache)
4. Browser Cache
5. Server Cache
이렇게 캐시에는 여러 종류의 캐시가 존재하고, 각각의 역할을 수행한다. 다음은 각 캐시들의 의미와 역할을 정리해놓은 것이다.
CPU Cache
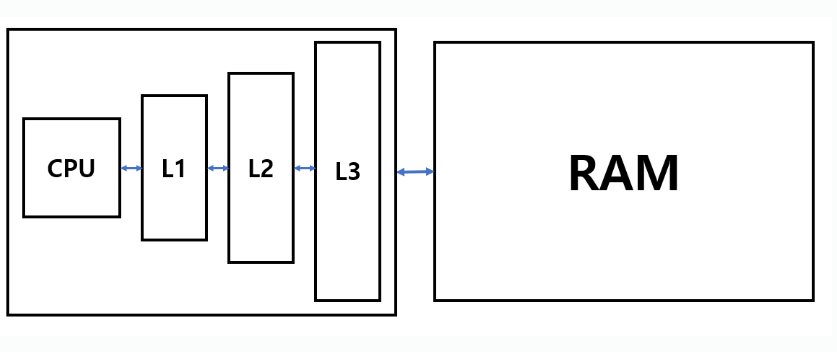
CPU와 RAM의 중간에 위치하여, 데이터를 임시로 저장하는 역할을 수행한다. 소위 논리회로나 컴퓨터구조 과목에서 다루는 캐시는 바로 이 저장소를 의미한다. 주로 SRAM으로 구현된다. (SRAM은 일반적인 RAM을 구성하는 DRAM보다 속도가 더 빠른 대신 가격이 비싸다.)
이 Cache에서 데이터 참조 속도는 CPU Register보다는 느리지만, RAM보다는 빠르다. CPU의 캐시에는 L1, L2, L3가 존재하며 여기서 'L'은 '레벨'을 의미한다. L1이 가장 빠르고 그 다음으로 L2가 빠르며, L3가 가장 느린 캐시다. CPU에서 데이터가 필요하면 L1을 먼저 참조하고, L1에 데이터가 없으면 L2를 참조, L2에도 데이터가 없으면 L3를 보는 식이다. 모든 캐시에 데이터가 없으면 그제서야 RAM을 들여다봐서 데이터를 가져온다. 즉, 여기서 Cache는 CPU가 RAM을 보기 전 중간 징검다리 역할을 하는 것이다. 만약 이 징검다리에서 원하는 데이터가 있다면, RAM까지 데이터를 탐색하지 않고 그대로 CPU에서 그 데이터를 활용하여 RAM 탐색하는 시간을 절약할 수 있다.
Disk Cache
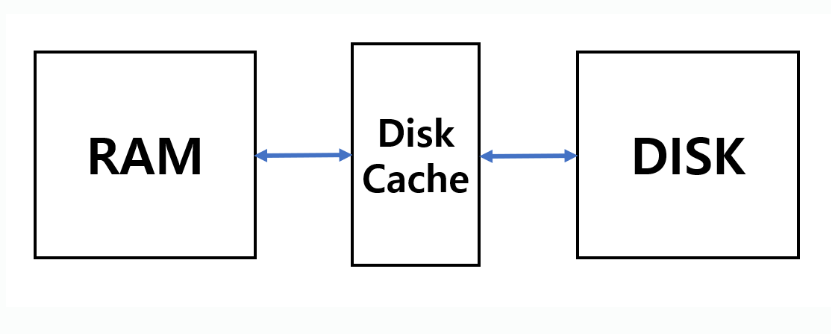
Disk buffer라고 하기도 한다. 데이터 읽는 속도를 향상 시키기 위해 RAM과 HDD 또는 RAM과 SSD 사이에 있는 저장장치를 의미한다. 이 캐시는 HDD에 내장되어 있을 수도 있고, RAM의 일부분을 빌려올 수도 있다.
Proxy Server (Web cache)
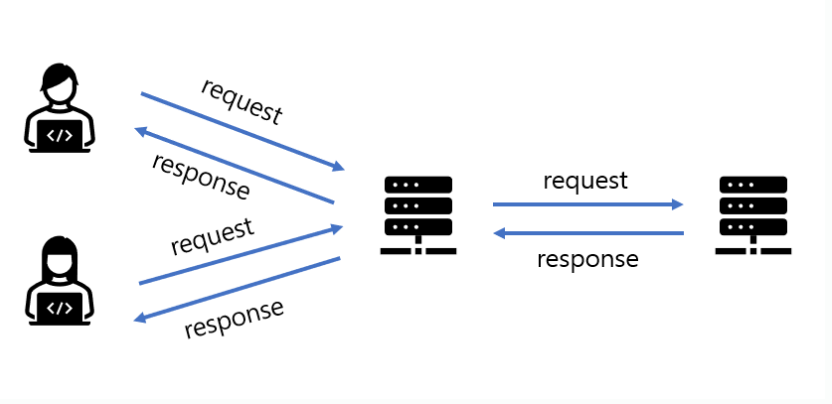
흔히 말하는 웹캐시는 이 프록시 서버를 의미한다. 프록시 서버는 원래의 서버를 대신하여 HTTP 요구를 처리하고 응답을 날리는 중간자 역할을 한다. 프록시 서버에는 자체적으로 디스크가 있어서 최근에 호출된 객체의 사본을 저장해두고 있으므로, 동일한 요청이 중복되어 서버로 전달될 때 그 요청을 중간에 가로채어 임의로 처리하고 응답을 클라이언트에게 보내준다. 이렇게 함으로써 원 서버에 들어가는 트래픽을 상당량 줄일 수 있는 것이다.
Browser Cache
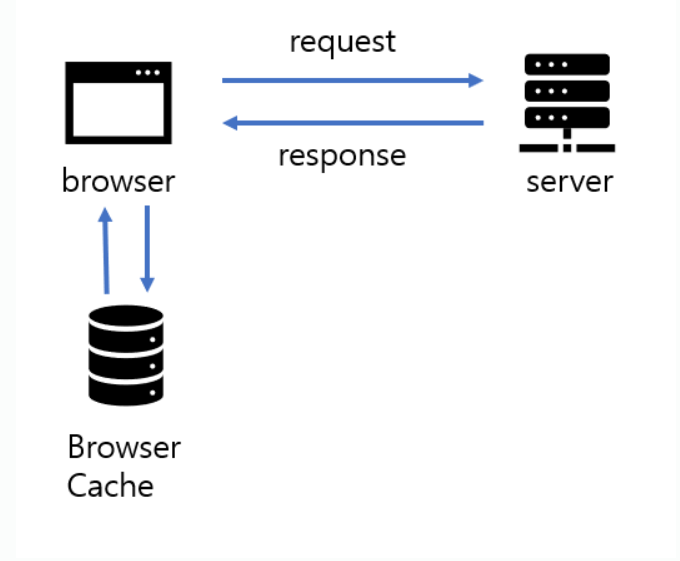
웹사이트가 특정 사이트를 방문하면, 브라우저는 페이지의 일부를 사용자의 컴퓨터 디스크에 저장한다. 여기서 페이지의 일부라 하면 해당 페이지의 HTML, CSS, Javascript, image 등 정적인 asset을 저장한다. (여기서 정적이라는 말은 방문할 때마다 변하지 않는 내용을 의미한다. 사용자에 따라 내용이 바뀌거나 방문할 때마다 바뀌는 내용은 '동적인 asset'이다.) 사용자가 다시 해당 페이지를 방문할 때 디스크에 저장된 페이지 요소를 가져와 로딩에 사용한다. 이렇게 하면 네트워크 지연 없이 바로 페이지를 렌더링할 수 있어서 사용자는 더 빠른 시간 내에 응답을 받아 페이지를 사용할 수 있게 된다.
Server side Cache
서버 쪽 캐시는 다양한 위치에서 사용될 수 있다.
하나는 다음과 같이 WAS가 DB를 참조할 때 사이에 캐시를 끼워넣어서 데이터를 읽는 속도를 향상시키는 용도로 사용하는 것이다. WAS와 DB 사이에 캐시를 넣으면 WAS가 DB를 읽기전에 캐시를 먼저 참조하고 데이터가 있으면 그 데이터를 그대로 사용하고 데이터가 없으면 DB에서 데이터를 읽어오고 캐시에 저장해두는 방식이다.

다른 한 가지는 아래와 같이 원 서버에 요청이 가기 전에 중간에 징검다리로 캐시 서버를 구축하여 중복 요청에 대해선 빠르게 응답할 수 있도록 만드는 것이다. API gateway를 사용하면 API gateway가 캐시 기능을 포함할 수 있기 때문에, 자주 요청되는 페이지는 네트워크 딜레이를 상당히 줄여서 사용자에게 응답으로 돌려줄 수 있다.
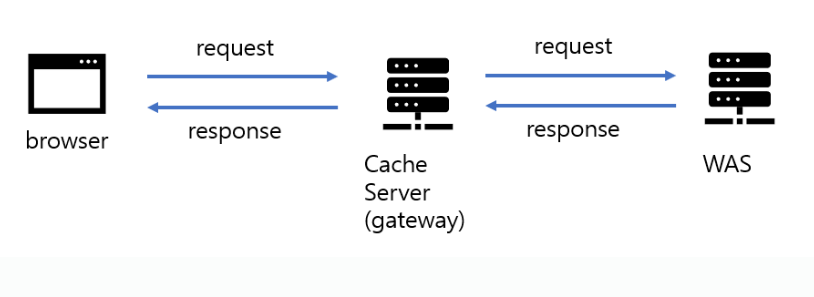
이 캐시 서버는 얼핏보면 웹캐시(프록시서버)와 비슷해보일 수 있으나, 여기에 구현된 캐시 서버는 어플리케이션 배포자가 서비스하는 서버로 ISP가 제공하는 프록시서버와는 다른 개념이다.
Computer science에서 cache의 의미
그렇다면 이것저것 다 저장하는 것은 전부 캐시냐? 하면 그건 또 아니다. 자세히 살펴보면 특정한 역할을 하는 저장소만을 캐시라고 지칭하는 것 같다.
위에 5가지 캐시에 대해 쭉 나열해보았다. 얼핏보면 중구난방으로 이 캐시 저 캐시를 나열한 것 같지만, 잘 살펴보면 각 캐시들에게서 공통점이 보일것이다. 그건 바로 '중간에 요청을 가로채서 원래의 저장소 대신 데이터를 돌려주어서 요청에 대한 응답을 빠르게 돌려주는 역할을 한다'는 것이다.
컴퓨터 하드웨어부터 보자. CPU Cache도 RAM을 참조하기 전에 Cache부터 살펴봐서 데이터를 가지고 있는지 먼저 살핀다. Cache가 해당 데이터를 가지고 있다면 수고로이 RAM을 살필 필요 없이 데이터는 CPU로 들어가게 된다. Disk Cache에도 비슷한 작용이 일어난다. 네트워크 쪽도 살펴보면 별반 다르지 않다. Browser Cache 같은 경우 사용자의 요청이 발생했을 때 해당 웹사이트의 페이지 조각을 Browser가 가지고 있다면 해당 데이터는 가져올 필요 없이 바로 캐시에서 꺼내서 렌더링된다. 프록시 서버도 마찬가지로 본인이 요청에 해당하는 데이터를 가지고 있으면, 원서버로 요청을 보내지 않고 중간에 요청을 가로채서 응답을 클라이언트에게 그냥 돌려주게 되는 것이다.
그러니까 정리하자면 이러한 특성을 가진 저장소는 Cache라고 불릴 수 있는 것이다.
1. 중간에서 요청을 가로챈다.
2. 데이터가 자신에게 있으면 원 저장소를 대신해서 응답을 돌려준다.
3. 해당 데이터가 없으면 원 저장소에서 데이터 가져와서 자신에게 저장함.
4. 무한히 자신에게 저장할 수 없으니, 자주 사용되지 않는 데이터는 삭제함.
5. 그러다보니 자주 사용되는 데이터 위주로 들고 있게 됨.
6. 요청하는 쪽은 캐시를 사용함으로써 응답 속도 측면에서 이득을 봄
Cache의 hit rate
이렇게 캐시는 특정 데이터 응답을 신속하게 받기 위해서 사용하는 중간 저장소라고 볼 수 있겠다. 다만 캐시의 저장소의 용량은 일반적으로 원 저장소의 용량에 비해 훨씬 작아서, 원 저장소의 데이터를 모두 가져올 수가 없다. (애초에 그럴거면 원 저장소를 사용할 이유가 없기도 하고) 그러면 기존에 있던 데이터를 삭제해줘야 하는데, 삭제 방식에는 여러가지 방식이 존재한다. 가장 대표적인 알고리즘은 LRU, LFU가 있다.
LRU: 가장 오랫동안 참조되지 않은 것을 삭제
LFU: 가장 적게 참조된 것을 삭제
어느 알고리즘을 사용하던 간에 캐시의 hit rate를 끌여올리는 것이 중요한 사항이다. 캐시의 hit rate는 요청을 보냈을 때 해당하는 데이터가 캐시에 있는 비율을 의미한다. 캐시에 있는 비율이 높을 수록 응답을 받는 평균 속도는 빠를 것일테니, 효율적인 캐시 사용이라고 볼 수 있다. 만약 cache의 hit rate가 너무 낮다면, 캐시를 사용하지 않는게 비용적으로 더 유리할 것이다.
글을 마치며
무심코 이것도 캐시 저것도 캐시라고 외웠다가 큰 혼란을 겪고나서 제대로 정리해보는 시간을 가지게 되었다. 결국 캐시라는 것은 물리적으로 특정한 저장소 위치를 의미한다기보다는 특정한 역할을 하는 저장소의 총칭이라고 봐도 될 것 같다. 물리적 의미보다 논리적 의미로 사용되는 단어인 것이다. 본 글이 캐시의 개념에 대해 혼란이 있었던 분들에게 도움이 되었으면 한다.
'Computer Science' 카테고리의 다른 글
| Idempotency(멱등성)과 REST API. Method의 idempotency는 가변적이다. (0) | 2024.02.10 |
|---|